AgentSelectBench
A unified-supervision benchmark for narrative query-to-agent recommendation: given a free-form natural-language request, rank deployable agent configurations.
Systematically converts heterogeneous evaluation artifacts (LLM leaderboards, tool-use benchmarks) into query-conditioned, positive-only interactions for training and evaluating agent recommenders at scale.
Benchmark Overview
AgentSelectBench comprises three complementary dataset parts, systematically covering LLM-only, toolkit-only, and compositional agent configurations.
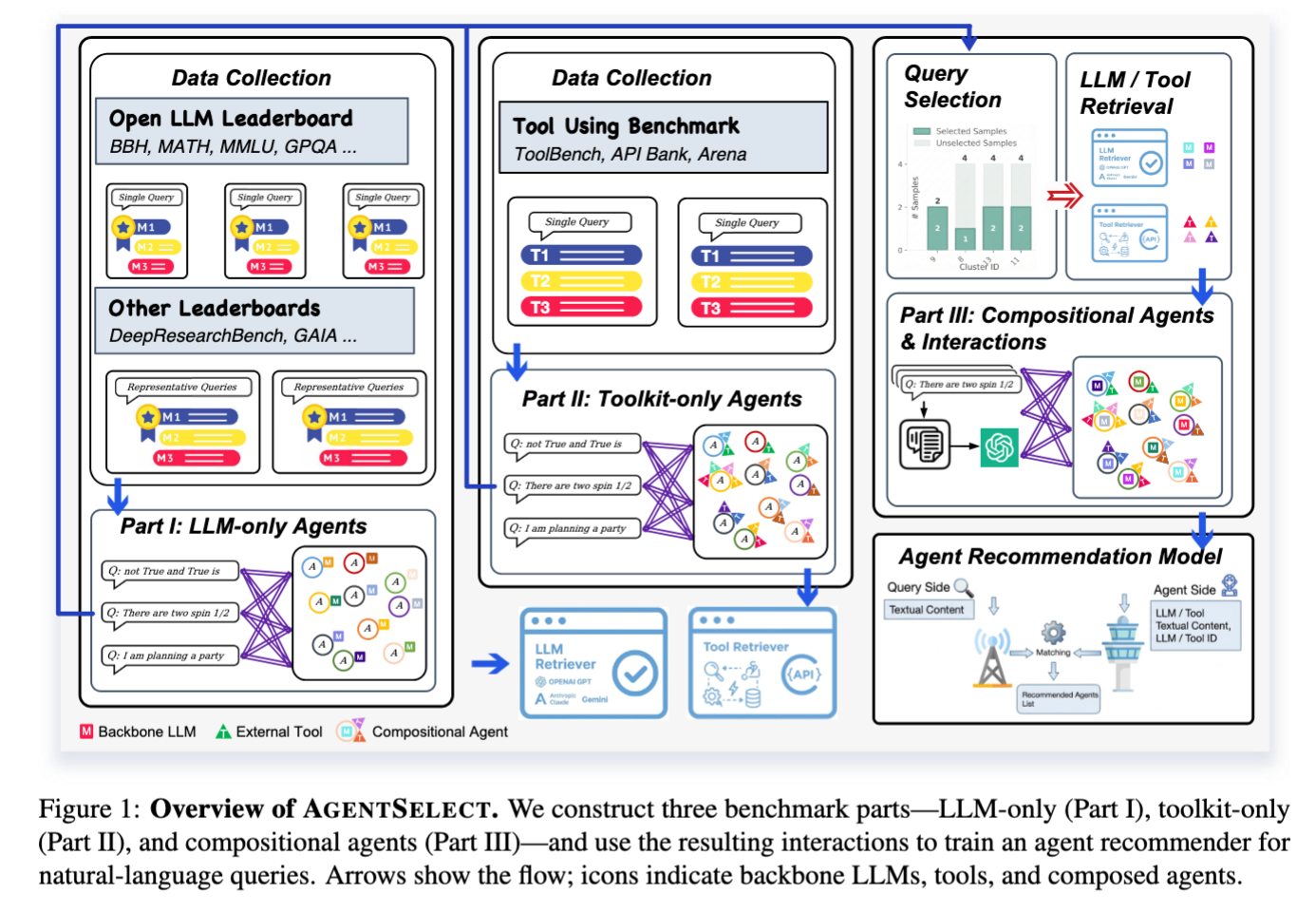
Figure 1: Overview of AgentSelect. Arrows show the flow; icons indicate backbone LLMs, tools, and composed agents.
Query-conditioned supervision derived from LLM evaluations/leaderboards (tools absent). Positives are constructed as top-k preferred backbones per query.
Tool-use benchmarks provide the required/reference toolkit for each query; we treat each query's toolkit as the positive target (backbone fixed to a placeholder).
Realistic (M, T) configurations by retrieving relevant components and composing them into candidate agents, yielding pseudo-positive interactions.
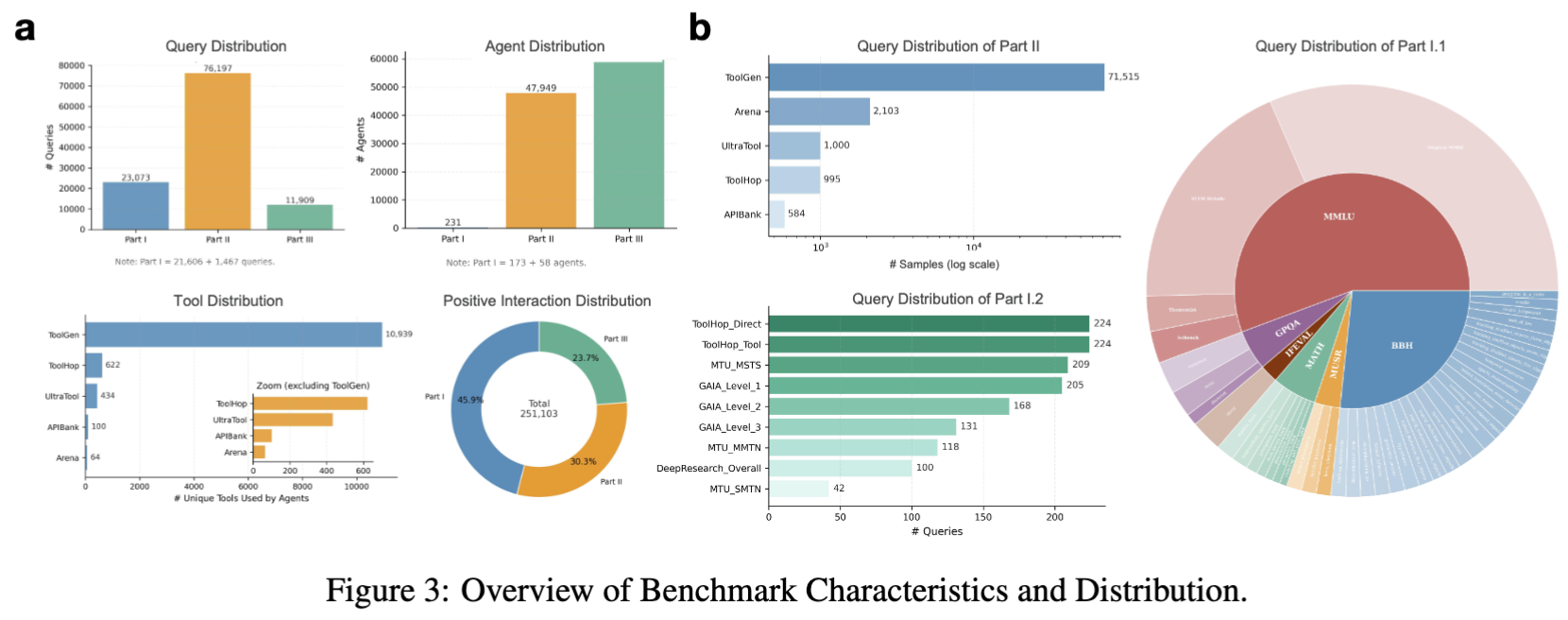
Benchmark Characteristics
Interactive visualizations of the benchmark distribution across queries, agents, tools, and interactions.
Note: Part I = 21,606 + 1,467 queries
Note: Part I = 173 + 58 agents
# Unique Tools Used by Agents
Total: 251,103 interactions
Agent Configuration
Each agent is represented as a capability profile with backbone LLM, toolkit, and configuration settings.
Session History:
Memory Management:
Knowledge Integration:
Table 1: Example of Agent Configuration - Stored as YAML configuration to keep agents deployable.
Leaderboard Results
Query-to-agent recommendation results on Parts I-III. Language embedding models marked with * are trained with in-domain supervision (fine-tuned).
| Method | Category | Prec. | Rec. | F1 | NDCG | MRR |
|---|---|---|---|---|---|---|
| 1GenRec | Generative | 0.9215 | 0.9255 | 0.9230 | 0.9404 | 0.9925 |
| 2NGCF | GNN | 0.8864 | 0.8959 | 0.8899 | 0.9125 | 0.9669 |
| 3MF | CF | 0.9200 | 0.9298 | 0.9237 | 0.9339 | 0.9631 |
| LightGCN | GNN | 0.8642 | 0.8730 | 0.8675 | 0.8820 | 0.9244 |
| KGAT | GNN | 0.8595 | 0.8688 | 0.8630 | 0.8733 | 0.9234 |
| DNN (Bert*) | DNN | 0.7336 | 0.7424 | 0.7369 | 0.7550 | 0.8889 |
| SimGCL | GNN | 0.8050 | 0.8137 | 0.8083 | 0.8290 | 0.8868 |
| DNN (Bert) | DNN | 0.7257 | 0.7345 | 0.7290 | 0.7469 | 0.8787 |
| LightFM | CF | 0.4679 | 0.4731 | 0.4698 | 0.5269 | 0.8010 |
| TwoTower (TFIDF) | TwoTower | 0.6831 | 0.6926 | 0.6867 | 0.7111 | 0.8003 |
| TwoTower (BGEM3) | TwoTower | 0.7065 | 0.7163 | 0.7102 | 0.7071 | 0.7820 |
| DNN (TFIDF) | DNN | 0.2971 | 0.3029 | 0.2993 | 0.3193 | 0.5743 |
| EasyRec* | LLM | 0.2565 | 0.2632 | 0.2590 | 0.2708 | 0.4969 |
| KaLM-v2.5* | LLM | 0.2850 | 0.2950 | 0.2888 | 0.2787 | 0.4052 |
| BGE-Rerank* | Rerank | 0.1370 | 0.1373 | 0.1371 | 0.1468 | 0.3560 |
| BGE-Rerank | Rerank | 0.0265 | 0.0275 | 0.0269 | 0.0283 | 0.0689 |
| EasyRec | LLM | 0.0150 | 0.0150 | 0.0150 | 0.0155 | 0.0353 |
| KaLM-v2.5 | LLM | 0.0170 | 0.0170 | 0.0170 | 0.0164 | 0.0321 |
Getting Started
Quick setup guide to run AgentSelectBench baselines and experiments.
# Clone from anonymous repository
# https://anonymous.4open.science/r/AgentMatch-F950
cd AgentSelectBenchpython -m venv .venv
source .venv/bin/activate # Linux/Mac
# .venv\Scripts\activate # Windows
pip install -r requirements.txtpython run_bpr_mf_knn.py \
--data_root /path/to/dataset_root \
--device cuda:0 \
--epochs 5 --batch_size 4096 --factors 128 --neg_per_pos 1 \
--knn_N 3 --eval_cand_size 100 --score_mode dotEvaluation Protocol
- Part I: Top-10 positives
- Part II: Top-1 positives
- Part III: Top-5 positives
- Ranking cutoff: Top-10
Reported Metrics
- Precision@10
- Recall@10
- F1@10
- nDCG@10
- MRR@10
Key Directories
- agent_rec/data/
- agent_rec/features/
- agent_rec/models/
- agent_rec/eval/
- scripts/
If you find AgentSelectBench useful, please cite our work:
@article{agentselect2025,
title={AgentSelect: A Unified Benchmark for Query-to-Agent Recommendation},
author={Anonymous},
journal={ICML 2025 Submission},
year={2025}
}